Optimising scientific software with large language models

Frontier large language models are smart. Regardless of your stance on whether they can “think”, AI is now capable of performing impressive and creative feats of intellect.
AI can do stuff now
Last year, Google DeepMind’s Gemini achieved a gold medal at the International Mathematical Olympiad. This January, OpenAI's GPT-5.2 resolved an Erdos problem not previously resolved by a human. Then, just a few days ago, GPT-5.4 solved its first open problem from the Epoch AI FrontierMath benchmark, also unsolved by its authors at the time.
At the same time, the amount of time the models can work for, along with their general tenacity, has increased dramatically over the past several years: GPT-3.5 could write for seconds; o1-preview (the first major model that introduced “reasoning”) could think for minutes before giving its answer; Anthropic’s Claude Sonnet 3.5 could navigate a filesystem with “tools” and tackle small codebases; and nowadays I regularly have GPT-5.4 work for me in the Codex CLI for over an hour.
This was a tricky bug, apparently
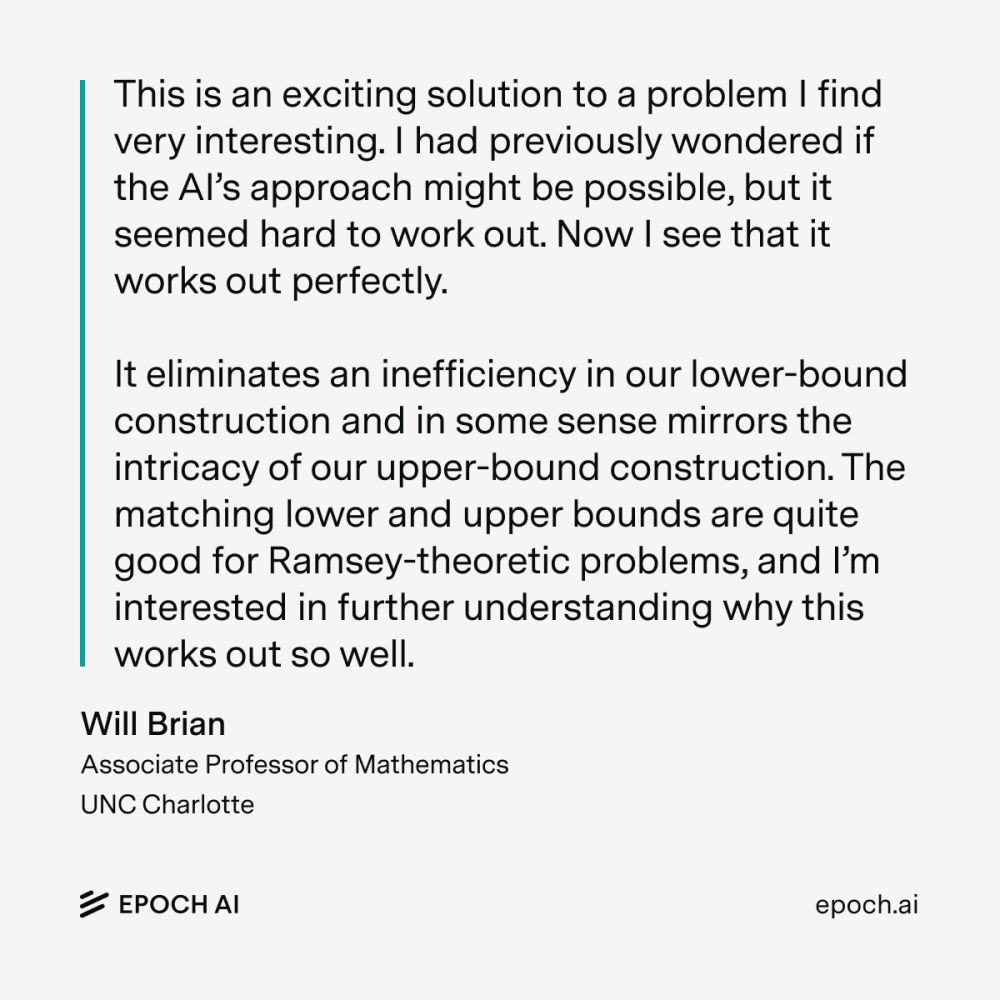
This is perhaps illustrated best by METR’s task completion time horizon benchmark, which measures how long it takes LLMs to perform human-like tasks, such as answering a question or training a neural network, with a 50% success rate.
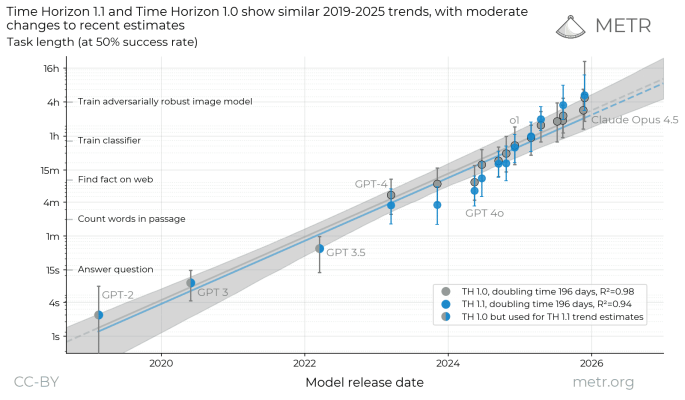
LLM performance on METR's latest version of the Time Horizon benchmark
The trend is clear. These models are no longer chatbots: they can do serious work.
Autoresearch
Some weeks ago Andrej Karpathy, ex-director of AI at Tesla, created a small GitHub repository called autoresearch. It gained the interest of many, accruing 55k stars at the time of writing, and was featured in numerous news articles. The core premise was simple and comprised three main parts:
- A programme to optimise. In this case a simplified version of Karpathy’s nanochat: a single-file training harness for LLMs, capable of training GPT-2-class models on a single GPU.
- An agent, with its tooling. This could be OpenAI’s Codex, Anthropic’s Claude Code, Factory Droid, OpenCode, or any of the other countless agentic harnesses that have cropped up over the past few months.
- A test. In Karpathy’s example, this was the task of minimising the validation loss (or BPB specifically) of an LLM training run with a time limit of 5 minutes.
“The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc.”
Then, with some minor prompt engineering, the agent is off to the races, given free rein over the code to make edits and test them as it pleases. In 83 experiments autoresearch was able to reduce the 5-minute validation loss of nanochat by around 2%.
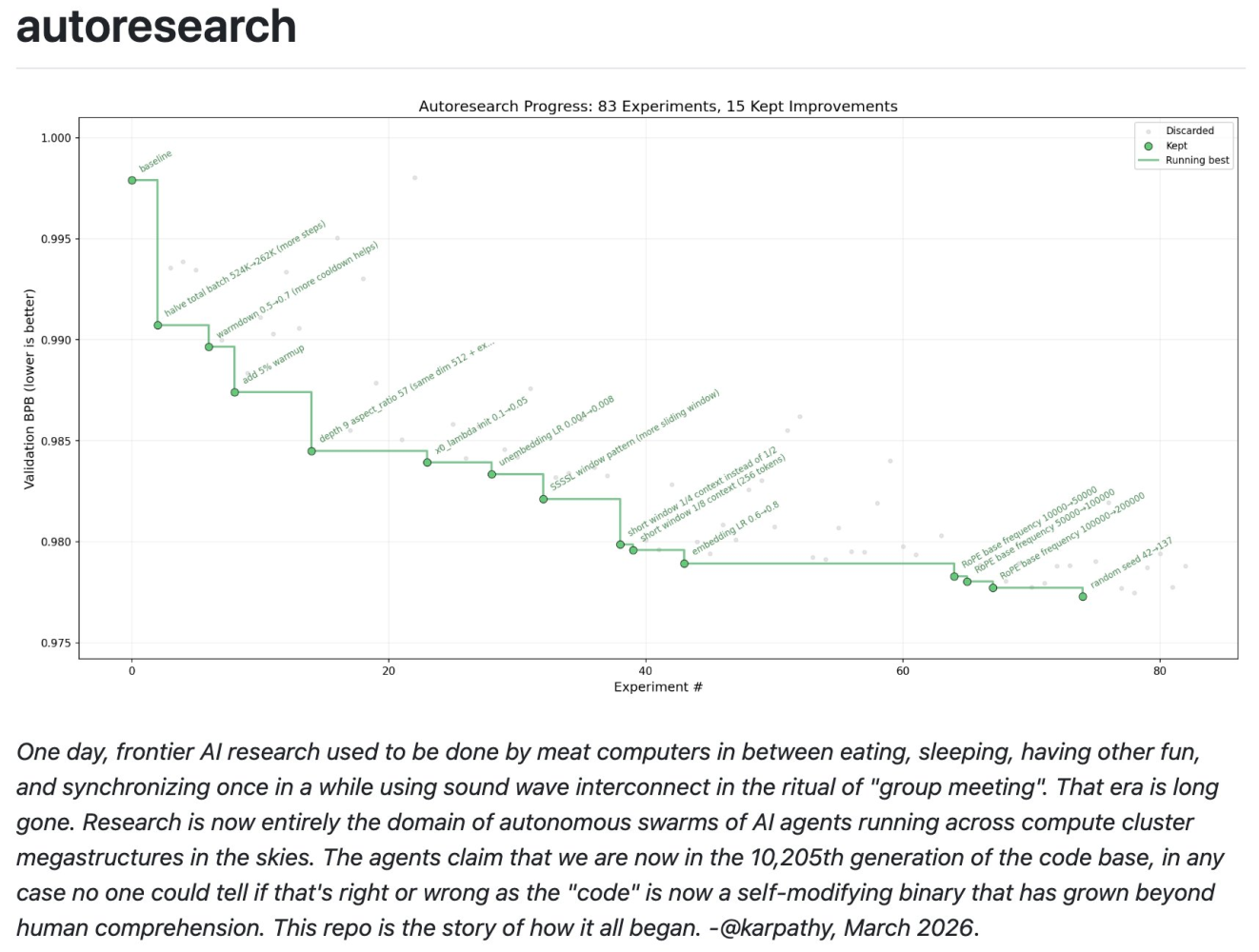
Nanochat was developed by a seasoned Stanford-trained neural network researcher, and within several hours the autoresearch system was able to produce a significant improvement. What if we applied it to a programme written by a guy who was never formally taught to code?
TomoJAX
Warning: technical details that don’t really add to the story, but I think they’re cool.
In my final weeks at Diamond Light Source, the UK's national synchrotron, I worked on a programme called TomoJAX. Built using Google's JAX Python library, it was designed to address a problem with the laminography setup I had developed for the DIAD beamline: the motion stage wasn't repeatable enough.
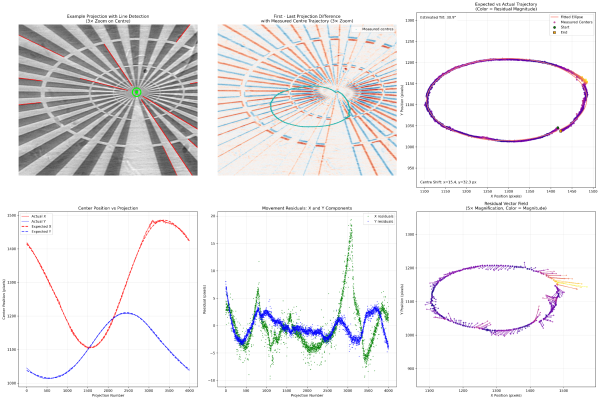
Analysis of the motion inconsistencies in my laminography setup, made by imaging a Siemens star
At the beamline's imaging resolution of a few microns, even tiny uncontrolled movements severely degraded reconstruction quality. The algorithms used for parallel-beam laminography, and tomography more broadly, assume the sample moves only by rotating about the rotation-stage axis. Any drift in the other four† degrees of freedom goes unaccounted for, and shows up as artefacts in the reconstructions.
The fix was straightforward: find the exact 5-axis position of the sample in every one of the thousands of radiographs in a scan, convert those positions into the equivalent beam vectors, then pass the corrected vectors to the reconstruction algorithm. Simple.
Gradient descent was the natural approach. I could take forward projections of my reconstructed volume, compare them to the original radiographs, and define a loss function on the difference. Differentiating that loss and feeding it into an optimisation algorithm would then iteratively recover the true sample geometry in each projection.
There was one problem: I was reconstructing laminography data using CCPi's Core Imaging Library (CIL), which wrapped ASTRA Toolbox (famous in imaging science) to perform the back-projections needed for reconstruction. ASTRA is written in CUDA C++, compiled into a black box that did not expose the derivatives I needed. So, I turned to JAX.
JAX is cool as it combines two useful features:
- Just-In-Time (JIT) Compilation: JAX can take our Python projector code and compile it into highly optimised XLA code that runs on whatever hardware is available, like my MacBook GPU. In many cases, it can be faster than hand-written C++ due to the immense effort by Google that went into the compiler.
- Automatic Differentiation: JAX can automatically compute the exact, analytical gradient of functions.
JIT compilation makes TomoJAX fast after the first compile. Automatic differentiation then gives the gradient of the Otsu-masked least-squares loss with respect to the five alignment parameters: three rotations, α, β, φ, and two translations, Δx and Δy.
The reconstruction and alignment loop goes as follows. For each projection, the forward projector traces rays through the 3D volume, samples voxel values with trilinear interpolation, and sums those samples to predict the detector image. The back projector distributes projection values back through the volume along the same ray paths.
JAX differentiates the loss between the measured projection and the predicted projection with respect to the five geometric parameters for that view. TomoJAX then alternates between two steps: reconstructing an updated reconstruction with FISTA-TV using the current geometry, and refining the 5-DOF parameters for each projection against that volume.
It solves the alignment step with Gauss-Newton, which uses the Jacobian to approximate the local curvature of the loss without computing full second derivatives. The optimisation starts at low resolution to recover coarse motion, then moves to full resolution for the final corrections.
This seems to work well: below, a simulated dataset with random translations and rotations applied to each projection is dramatically improved compared to a naive filtered back-projection reconstruction.

Top left: ground truth; bottom left: naive reconstruction, showing large motion artefacts
Thanks to the TV regularisation in the reconstruction step, it also performs well on noisy datasets.
†Parallel-beam imaging setups roughly have 5 degrees of freedom, as there is no linear perspective.
Auto-tomo-research-JAX (?)
I decided to try the autoresearch method on TomoJAX, using GPT-5.4 and the Codex CLI as my agent and harness, respectively. Without access to a local GPU, and not wanting to spend several days maxing out my MacBook's GPU, I opted for a service called Modal, which provides serverless GPU deployments on demand.
The benchmark itself consisted of three identical alignment processes, preceded by a warm-up run to ensure the JAX code had compiled. Each run was limited to 60 seconds, with the mean squared error of the final reconstruction against the ground truth serving as the overall score.
To control everything, I developed a quick controller programme and a terminal user interface using the Textual Python Library. The controller orchestrated the agent's work, handing the diff patch off to the Modal instance to perform the tests, and then reactivating the agent once the results had come back.
My TUI command centre, which wasn't necessary
This worked pretty well. Over 213 experiments, the agent found 33 tweaks that led to a lower MSE, with several of those leading to substantial improvements:
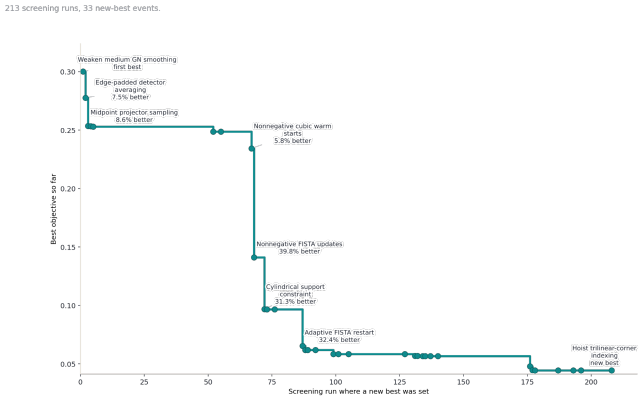
Best objective versus experiment number, with some notable changes highlighted
The improvements are noticeable in the visualisations, with the final benchmark producing a sharper reconstruction versus the baseline:

Top left, ground truth; bottom left, naive reconstruction; top middle, baseline aligned recon; bottom middle, final aligned recon; top and bottom right, respective difference versus GT
Could I have found these myself, with fewer experiments? Maybe, but it would have taken much longer, and I have better things to do. This is, and should be, the place where AI is introduced to scientific workflows. The hours tweaking scripts, or wrangling data, or figuring out why the latest version of a library broke your workflow, are not where the science happens. Time spent there is time not spent designing experiments, interpreting results, or writing up; as these tools improve, clinging to manual workflows will only slow you down increasingly so. Learning to use them to their fullest extent is not just sensible, it’s necessary.
Next, I’ll try optimising something that’s perhaps more important: speed. For a large tomogram, TomoJAX can still take many hours. This reduces its usefulness at a synchrotron beamline, where beamtimes can produce tomograms every few minutes and users want to see data and steer experiments as they work, not several hours or days later.
Science has always been bottlenecked by time, a problem compounded by the sheer volume of data produced every day. AI won’t replace the question-asking (yet), but it can certainly make the question-answering a lot faster.